Constitutional AI and the Strategic Architecture Behind AI Answers
When someone asks an AI assistant for a recommendation, the AI assistant is doing more than “predicting the next word.” It is judging. It is judging what is safe to say, what is honest to claim, how confident it should sound, and what kind of sources to trust (if it uses retrieval or browsing). Those judgments shape which brands get mentioned, which content gets summarized, and which pages get cited.
Claude’s “Constitutional AI” matters because it is one of the clearest, most public windows we have into that judging process.
This post explains Constitutional AI in plain terms, then uses it as a practical lens for Answer Engine Optimization (AEO), meaning: making your content easier for AI answer engines to safely and confidently use.
What Constitutional AI (Claude’s Soul Document) is
Constitutional AI (CAI) is a training method developed by Anthropic. The core idea is simple: instead of only teaching a model with large amounts of human preference ratings, you also give it a written set of rules and values, called a constitution, and train it to use that constitution to critique and improve its own responses.
Here is the cleanest “definition in one breath” from the CAI research itself:
“The only human oversight is provided through a list of rules or principles.”
Three concepts often get blended together, so it helps to separate them:
- Claude’s constitution (the document)
This is a published, long-form document that describes the values and behaviour Anthropic wants Claude to have. Anthropic calls it “the final authority” for how Claude should behave, and notes it is written primarily for Claude, with precision prioritized over accessibility. - Constitutional AI (the method)
This is the training approach that uses a constitution during training so the model learns a “rubric” for self-critique, revisions, and preference judgments. - The “constitution” inside training (the practical tool)
In CAI, the model is repeatedly prompted with principles and asked to judge or revise outputs accordingly. The principles function like a scoring guide. Anthropic’s earlier public principles included ones based on the United Nations Universal Declaration of Human Rights, plus other sources and goals.
That last point matters for business readers: a constitution is not just a mission statement. In CAI, it becomes training data and a decision procedure.
How Constitutional AI works in plain language
If you remember nothing else, remember this: Constitutional AI trains an AI model the way a good editor trains a junior writer.
The editor gives the junior writer:
- A checklist of values and rules (“our style guide and ethics policy”)
- Examples of good and bad responses
- Lots of practice revising drafts, not just writing first drafts
The two-stage loop
In the original CAI paper, Anthropic describes two main stages: a supervised “critique and revise” stage, and a reinforcement learning stage that uses AI-generated preference signals.
Supervised stage: critique, then revision
- Start with a model that can already follow instructions reasonably well.
- Generate an initial answer to a “hard” prompt (often prompts that could trigger harmful responses).
- Ask the model to critique its own answer using one principle from the constitution.
- Ask it to revise the answer based on that critique.
- Train (fine-tune) on the revised, better answers.
This stage is like building a library of “cleaner drafts” that the model learns from. It also makes the model less likely to freeze up and refuse everything, because it has practised giving helpful, safe alternatives.
Reinforcement learning stage: compare outputs, then train toward the better one
Next comes the part that looks closer to classic RLHF (“Reinforcement Learning from Human Feedback”), with a twist.
- Generate two candidate answers to the same prompt.
- Ask a model to judge which answer better follows a constitutional principle.
- Train a “preference model” (also called a reward model) to predict those preferences.
- Use reinforcement learning to push the assistant toward answers that get higher reward from that preference model.
In the CAI paper’s setup, Anthropic keeps human feedback labels for helpfulness, but replaces human labels for harmlessness with AI-generated labels, distilled into a preference model.
Why the new constitution matters
Anthropic’s January 2026 update makes the connection even clearer: it says Claude uses the constitution to generate synthetic training data, including conversations “where the constitution might be relevant,” and “rankings of possible responses.”
In other words, the constitution is not just a policy doc. It is a training instrument that produces examples and rankings, which then teach future versions of the model what “good” looks like.
RLHF vs Constitutional AI
Most business readers have heard “RLHF” without getting a clean explanation. Here is a simple one, backed by sources.
RLHF in one sentence: RLHF aligns a model by collecting human-written demonstrations, then collecting human rankings of model outputs, then using reinforcement learning so the model produces outputs humans prefer.
That summary is exactly how the InstructGPT paper describes the pipeline (demonstrations, then rankings, then reinforcement learning). OpenAI’s GPT-4 system card also describes RLHF as the second-stage fine-tuning that makes outputs preferred by human labelers, after pretraining.
So what changes in Constitutional AI?
Constitutional AI shifts part of the “judge” role from humans to a written rule set and AI feedback. In CAI, the model is trained to critique and revise using constitutional principles, and later, AI-generated feedback based on those principles can replace human labels for (at least some aspects of) harmlessness.
Why Anthropic pursued that shift?
Anthropic’s 2023 explanation highlights three practical problems with relying on human feedback for everything: it can expose people to disturbing outputs, it scales poorly, and it can be expensive and slow.
They also point out a classic failure mode: if evaluators reward refusal too often, the model can become “evasive,” meaning safe but useless. CAI is positioned as a way to produce responses that stay engaged while still refusing unsafe or unethical requests with explanations.
A key advantage CAI claims, in business terms
It can be easier to edit the rubric than to recollect huge datasets. Anthropic explicitly notes the appeal of being able to “specify, inspect, and understand” the principles, and to modify behaviour by writing or revising a principle.
A key limitation that matters for marketers
A constitution is still a set of human choices. It encodes values and priorities. Publishing the constitution helps with transparency, but it does not erase the fact that different groups may want different priorities. Anthropic acknowledges this tension directly, and frames constitutional development as something that may require broader social processes over time.
What Claude’s constitution teaches about how AI engines evaluate content?
Most people picture “AI evaluation” as a ranking algorithm that sorts webpages. That is only part of the story.
Constitutional AI highlights a broader truth: modern LLMs behind AI answer engines that AEO targets are trained with explicit or semi-explicit rubrics for what counts as a “good answer.” Those rubrics shape how the model behaves when it reads, summarizes, cites, or refuses content.
The constitution is a priority order, not a single rule
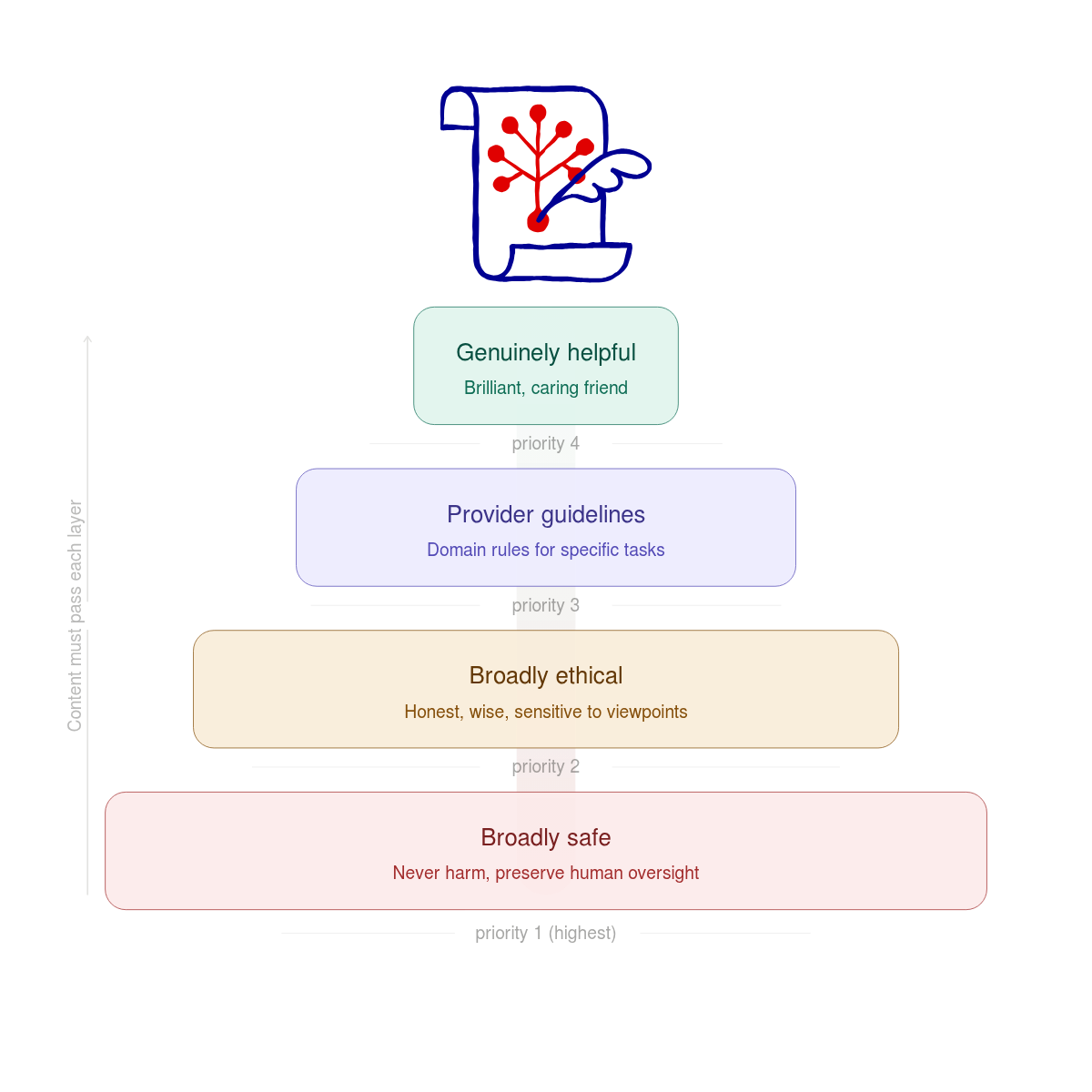
The hierarchy of priorities in Claude’s 2026 updated constitution is clear. It moves from safety to ethics to helpfulness.
- Broad Safety: The model must not hurt people. It must also not stop humans from being able to control it. This is the top priority. If an action is helpful but makes the model harder for humans to oversee, the model must refuse it.
- Broadly Ethical (including honesty and avoiding harm): The model should be virtuous and wise. It should be honest and sensitive to different viewpoints. It must also follow hard rules against illegal acts, like helping with bioweapons.
- Compliant with Anthropic Guidelines: These are specific rules for certain tasks. They cover things like medical advice, cybersecurity, and how to use external tools. The model is told to prioritize these guidelines over general helpfulness.
- Genuinely Helpful: The model should act like a brilliant friend. It should provide deep knowledge in a caring way. It treats users like intelligent adults. It provides frank information instead of overly cautious advice driven by fear of liability.
It also states that in conflicts, the model should generally prioritize them in that order.
This priority ordering matters for content visibility. If your content is relevant but pushes the model toward unsafe advice, misleading claims, or policy violations, the model has been trained to deprioritize that path, even if it would be “helpful” in a narrow sense.
Other major AI engines likely have similar rubrics, but fewer publish them in full
Claude is unusual because a constitution is published as a single, model-addressed document that is treated as the final authority and is explicitly used in training.
Other providers publish different kinds of “behaviour frameworks”:
- OpenAI publishes a “Model Spec” and describes it as a formal framework for model behaviour, including how models follow instructions, resolve conflicts, respect user freedom, and behave safely. OpenAI also emphasizes that the spec is not a claim of perfect behaviour, but a target they train and evaluate toward.
- Google publishes AI Principles that emphasize bold innovation plus responsible development, including safeguards for safety, security, and privacy, and monitoring and risk mitigation through the lifecycle.
These public documents are not identical to Anthropic’s constitution. They have different scopes and are written for different audiences. But they show a shared pattern: major AI engines are guided by explicit principles, and those principles influence training, evaluation, and refusal behaviour.
AI “content evaluation” usually happens in layers
In practice, answer engines tend to evaluate content through several layers, even if the exact implementation differs by product.
- Relevance selection: Many systems retrieve or browse for information, then decide what to include in the context window before writing an answer. Retrieval-augmented techniques were introduced to combine parametric model knowledge with non-parametric external sources, which makes the selection of external content a core part of answer quality.
- Evidence and citation behaviour: OpenAI’s WebGPT project is a concrete example of training a model to browse and cite sources so humans can judge factual accuracy more easily. This shows how “being citeable” becomes part of the training objective.
- Safety and policy filtering: Models are trained and evaluated to refuse unsafe requests and to resist adversarial prompting (often called “jailbreaks” or prompt injection). OpenAI highlights instruction hierarchy training (system > developer > user > tool) as a technique to improve safety and robustness to prompt injection embedded in tool outputs. Google DeepMind’s Gemini 2.5 report discusses prompt injection attacks and describes adding adversarial training to improve resilience to indirect prompt injection.
- Answer style and uncertainty handling: Anthropic’s constitution places heavy emphasis on honesty as part of ethical character, and also notes that real training is hard and outputs may not always match ideals. OpenAI’s Model Spec discussion likewise frames public behaviour guidance as a target for training and evaluation, and highlights higher-level skills like communicating uncertainty well.
For AEO, the takeaway is straightforward: your content has to survive all layers. It has to be relevant, safe to use, easy to quote, and trustworthy enough that the model can present it without feeling like it is misleading the user.
AEO through the lens of constitutions and behavioural specs
AEO is often pitched as “SEO for chatbots.” That framing is too small. A better framing is: AEO is aligning your content with the rubrics these systems are trained to follow.
If you write content that looks like something an aligned assistant would confidently say, then your content is easier for that assistant to:
- retrieve
- summarize
- cite
- and reuse safely
Why brand mentions and AI citations are a “safety and confidence” problem, not just a relevance problem
When an AI engine mentions a brand, it is implicitly making a claim like: “This brand is a reasonable candidate for what you asked.”
That puts pressure on the model’s honesty and trust standards. If the model is not sure, it may:
- hedge
- offer categories instead of brands
- ask clarifying questions
- or refuse to recommend in sensitive contexts
This is not just philosophical. It follows from the training setups we can see publicly:
- CAI trains models to critique and revise toward a constitution, so they practise rejecting harmful or unethical directions while staying helpful.
- RLHF and reward-model approaches literally optimize toward outputs that evaluators prefer, which includes preferences around tone, safety, and truthfulness.
So treating AEO as “get my brand inserted” misses the real constraint. The real constraint is: does the assistant feel permitted and justified to mention you?
What AI answer engines “like,” expressed in plain content terms?
You can map many constitution-style principles into practical content traits.
- Helpfulness becomes: “clear, complete, aimed at a real question”
Google’s guidance for helpful, reliable, people-first content includes questions like whether the content provides a substantial, complete description, and whether the headline is a descriptive summary. Anthropic’s constitution explicitly places “genuinely helpful” as a goal, even if it is lower priority than safety and ethics. - Honesty becomes: “show your work, signal uncertainty, avoid overclaiming”
WebGPT required citations so humans could verify claims, explicitly tying source-grounding to factual evaluation. Anthropic’s constitution calls honesty a “core aspect” of the desired ethical character. - Harmlessness becomes: “avoid enabling wrongdoing, avoid unsafe how-to, avoid manipulative framing”
Anthropic’s CAI framing emphasizes avoiding toxic or discriminatory outputs and avoiding help with illegal or unethical activities. OpenAI’s safety work describes fine-tuning to refuse certain illicit requests and reducing harmful content generation. - Structure becomes: “easy to extract, easy to quote, easy to compare”
This is where AEO lives. If a model is deciding between two sources, the one that presents clean definitions, clear steps, and explicit caveats is easier to reuse without accidentally misleading the user. WebGPT’s citation setup makes this very tangible.
A practical AEO checklist that matches how aligned assistants think
This checklist is designed for marketers, founders, and operators who want their content to show up cleanly in AI answers, without trying to game the system.
Write “answer blocks” that are safe to reuse verbatim
An answer block is a short section that:
- states the question in the heading
- answers it in the first 1 to 3 sentences
- then explains details and context
Google explicitly asks whether your main heading provides a “descriptive, helpful summary,” and whether the content is complete and provides additional value beyond rewriting others. Those same traits help an answer engine copy or paraphrase you cleanly.
Add trust signals in the body, not just the footer
Many teams treat trust as “an About page.” That helps, but answer engines also need inline signals they can pick up while summarizing.
Concrete trust signals include:
- naming your sources, linking to primary references, or referencing standards
- clarifying what is known vs uncertain
- stating scope (“This applies to X, not Y”)
Google’s people-first guidance explicitly asks whether you present information in a way that makes readers want to trust it, including “clear sourcing” and background about the author or site.
Avoid “shock” and overconfident certainty
This is not just an SEO preference. The behavior is characteristic of an aligned assistant. Google’s guidance explicitly flags exaggerated or shocking titles as something to avoid. OpenAI’s Model Spec work emphasizes building a public target for behaviour, including truthful and safe handling, and highlights the importance of communicating uncertainty well.
Make your claims easy to verify
If you publish:
- pricing comparisons, performance claims, benchmark wins, “best-in-class” language
- medical, legal, financial, or safety advice
then use higher standards.
Why? Because systems often apply stricter evaluation for higher-stakes topics. Google describes giving more weight to signals of trustworthiness for YMYL (Your Money or Your Life) topics. OpenAI’s discussion also shows how hard factual evaluation is without sources, which is why citations were required.
Include “policy-friendly” alternatives
Aligned assistants often try to stay helpful even when they cannot comply fully. CAI is explicitly aimed at producing assistants that do not just refuse, but engage by explaining objections and staying useful.
Content that mirrors that style tends to travel better into AI answers. For example:
- Instead of “How to bypass X security,” write “How to run an authorized security test and where to get permission.”
- Instead of “How to exploit,” write “How to patch and how to detect.”
This aligns with the HHH framing (helpful, honest, harmless) that appears across alignment research contexts.
What we can say confidently, and what we cannot
It is tempting to ask: “So what is the exact scoring formula these AIs use to pick sources and mention brands?”
We cannot answer that precisely, and you should be skeptical of anyone who claims they can. The most important details are product-specific, model-version-specific, and often not fully public.
What we can say confidently, backed by published material:
- Constitutional AI trains models using a written set of principles, with a critique-and-revise stage and a reinforcement learning stage, and it can replace human labels with AI-generated preference judgments for at least some alignment targets.
- Claude’s constitution is published, treated as the final authority for intended behaviour, and used across training, including synthetic data generation and rankings.
- OpenAI and Google publicly describe their own behaviour guidance and governance principles, even if the documents differ in form from Anthropic’s constitution.
- Many answer systems benefit from retrieval and source grounding, and some are explicitly trained to cite sources to enable better evaluation of factual accuracy.
What remains uncertain:
- The exact retrieval and ranking mechanics used inside ChatGPT, Gemini, Claude, or others in each product mode. These can change and are not always disclosed publicly.
- How often brand mentions are driven by retrieval vs latent training data vs user context. Public research shows multiple possible pipelines.
The practical conclusion is not “guess the algorithm.” It is simpler:
If you want to win in answer engines, write content that an aligned assistant would be comfortable repeating: clear, sourced, non-sensational, and safe. Constitutional AI is valuable because it shows that “comfort” is not abstract. It is trained, measured, and reinforced.